About Me
I am a research scientist leading multimodal foundation model research at Amazon AGI. My work focuses on compute-efficient vision encoder training, cross-modal alignment, and scaling ladder design — shipped in Amazon Nova and Amazon Nova Multimodal Embeddings. I serve as an Area Chair for ECCV and have published at ICLR, ECCV, and IEEE TIP. I received my Ph.D. from Georgia Tech under Dr. Ghassan AlRegib, where I developed gradient-based representations for anomaly detection grounded in information geometry.
Please check my CV for more information.
News:
- Jun. 18, 2026: MKP-Adapter is accepted for publication at ECCV 2026.
- Jan. 3, 2026: Serving as an Area Chair for ECCV 2026.
- Oct. 23, 2025: Amazon Nova Multimodal Embeddings model is launched.
- May 10, 2025: Recognized as a CVPR 2025 Outstanding Reviewer.
- Dec. 3, 2024: Amazon Nova Multimodal Foundation model is launched.
- Nov. 29, 2023: Amazon Titan Multimodal Embeddings model is launched.
- May 16, 2023: Recognized as a CVPR 2023 Outstanding Reviewer.
- Jan. 20, 2023: MaskVLM is accepted for publication at ICLR 2023.
- Jul. 3, 2020: GradCon is accepted for publication at ECCV 2020.
- Sept. 24, 2019: Won the Best Paper Award (top 0.1%) at IEEE ICIP 2019.
Experience
Amazon AGI
Senior Applied Scientist
October 2023 - Present
- Led vision encoder training and data mixture optimization for Amazon Nova (multimodal understanding) and Amazon Nova Multimodal Embeddings (universal retrieval across image, text, document, video, and audio).
- Designed a multi-stage vision encoder training curriculum — compute-efficient contrastive learning in early stages, followed by end-to-end training with the LLM — achieving equivalent performance at 25% of the compute budget.
- Optimized multimodal data mixtures across pre-training and SFT stages; developed a scaling-based methodology to identify per-dataset contribution and saturation.
- Established scaling ladders to identify optimal batch size, learning rate, and model size for contrastive learning; trained vision encoders with native resolution support by investigating positional embedding interpolation strategies.
AWS AI Labs
Applied Scientist
January 2021 - October 2023
- Proposed MaskVLM, a cross-modal masked reconstruction method that learns vision-language alignment by reconstructing one modality’s masked signal conditioned on the other, achieving state-of-the-art on retrieval, VQA, and visual reasoning (ICLR 2023).
- Curated billion-scale web training data with synthetic caption enrichment and designed multi-encoder architectures for large-scale contrastive learning, significantly improving retrieval performance. Shipped as Amazon Titan Multimodal Embeddings.
Georgia Tech
Graduate Research/Teaching Assistant
January 2016 - December 2020
- Developed gradient-based representations for anomaly and out-of-distribution detection, achieving state-of-the-art performance across diverse image recognition datasets (ECCV 2020, ICIP Best Paper 2019).
- Grounded gradient-based representations theoretically using Fisher kernel from information geometry.
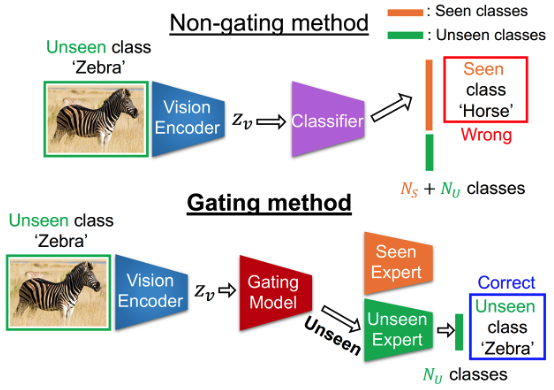
- Developed a gating model for generalized zero-shot learning that calibrates bias toward seen classes (IEEE TIP 2022).
Selected Publications
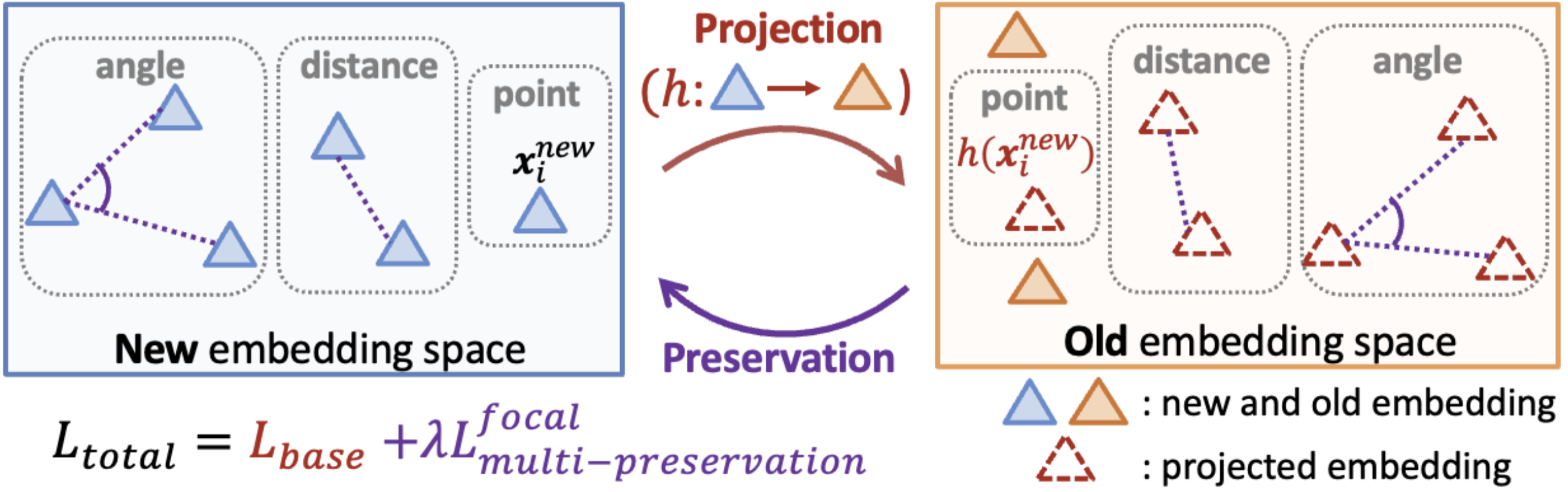
J. Byun, G. Kwon, H. Hsu, M. Karumuri, Z. Zhang, H. Yang, and D. Modolo, “Multi-modal Knowledge Preserving Adapter for Embedding Backward Compatibility,” European Conference on Computer Vision (ECCV), 2026.
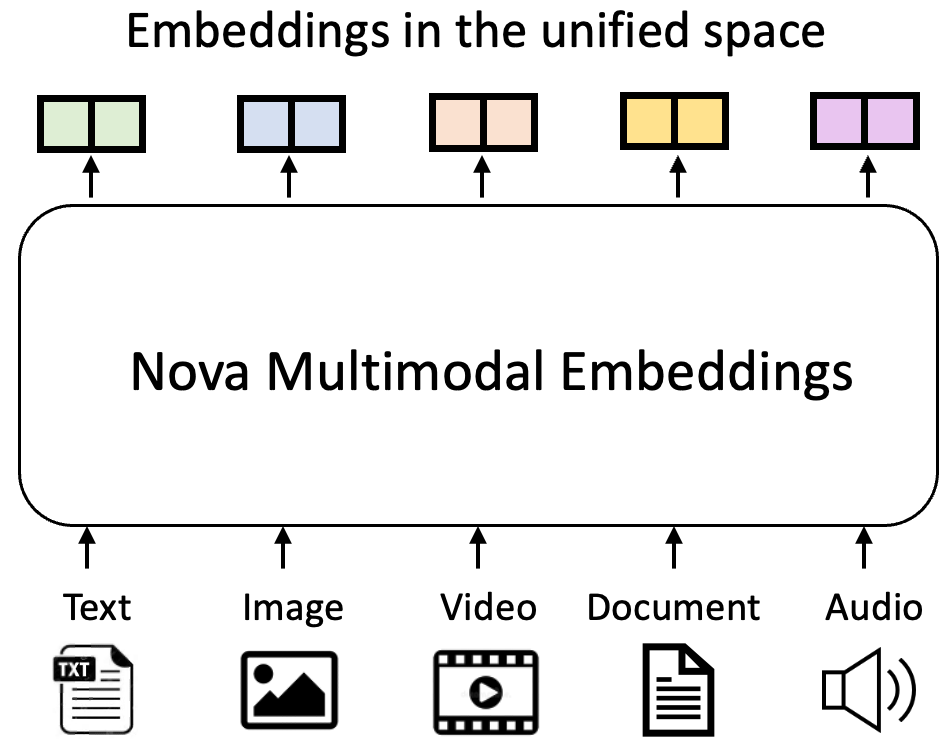
Amazon Artificial General Intelligence, “Amazon Nova Multimodal Embeddings: Technical Report and Model Card,” Tech report, 2025.
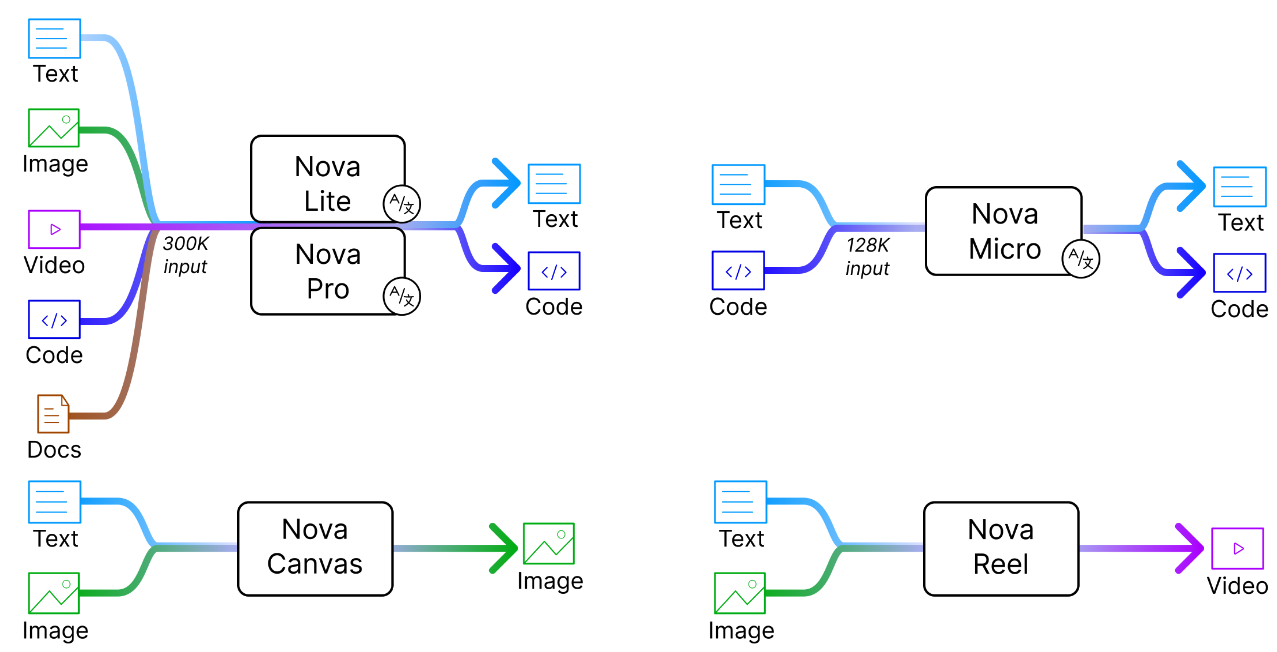
Amazon Artificial General Intelligence, “The Amazon Nova Family of Models: Technical Report and Model Card,” Tech report, 2024.
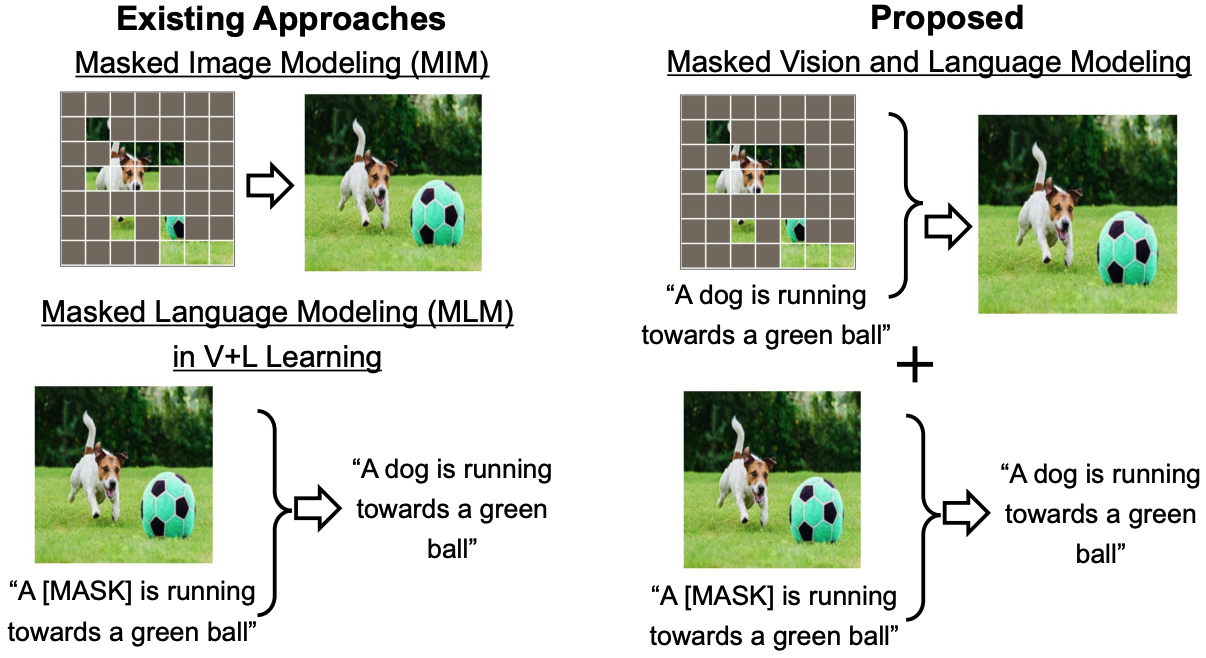
G. Kwon, Z. Cai, A. Ravichandran, E. Bas, R. Bhotika, and S. Soatto, “Masked Vision and Language Modeling for Multi-modal Representation Learning,” International Conference on Learning Representations (ICLR), 2023.
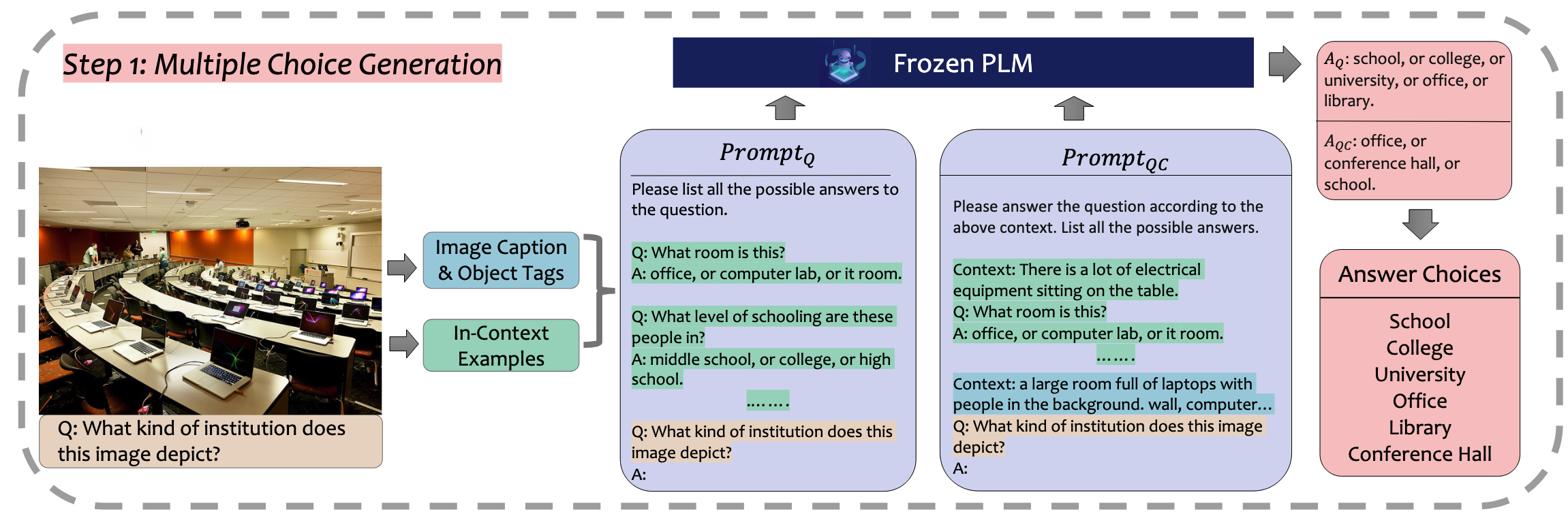
X. Fu, S. Zhang, G. Kwon, P. Perera, H. Zhu, Y. Zhang, A. Li, W. Wang, Z. Wang, V. Castelli, P. Ng, D. Roth, and B. Xiang, “Generate then Select: Open-ended Visual Question Answering Guided by World Knowledge,” The 61st Annual Meeting of the Association for Computational Linguistics (ACL) Findings, 2023.
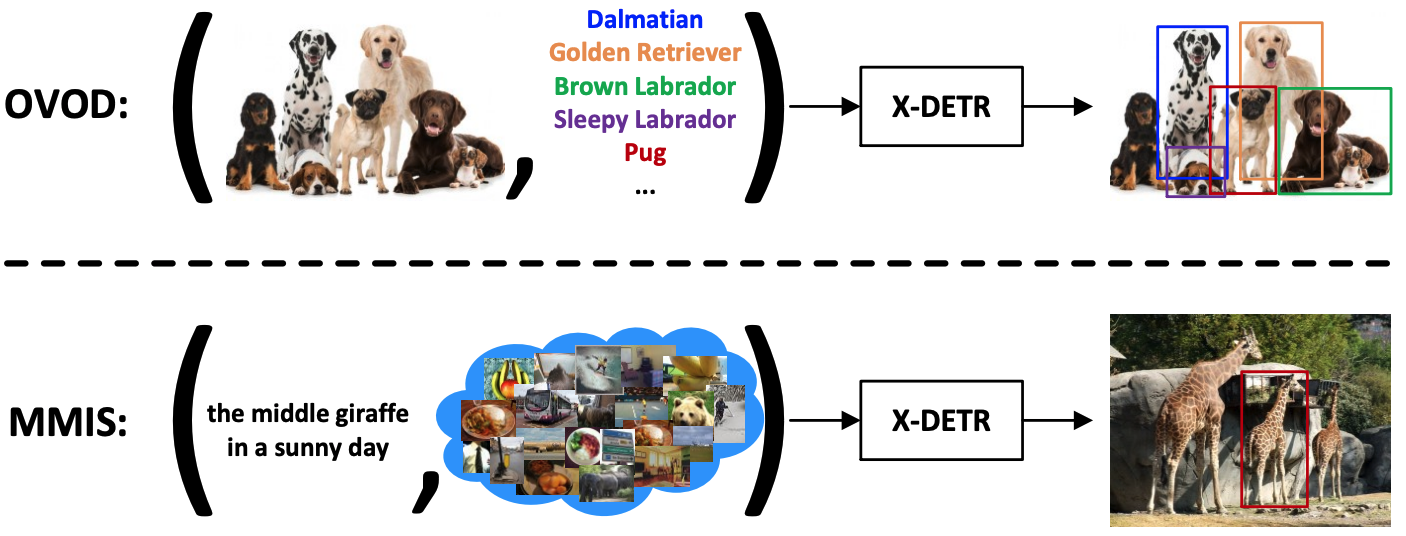
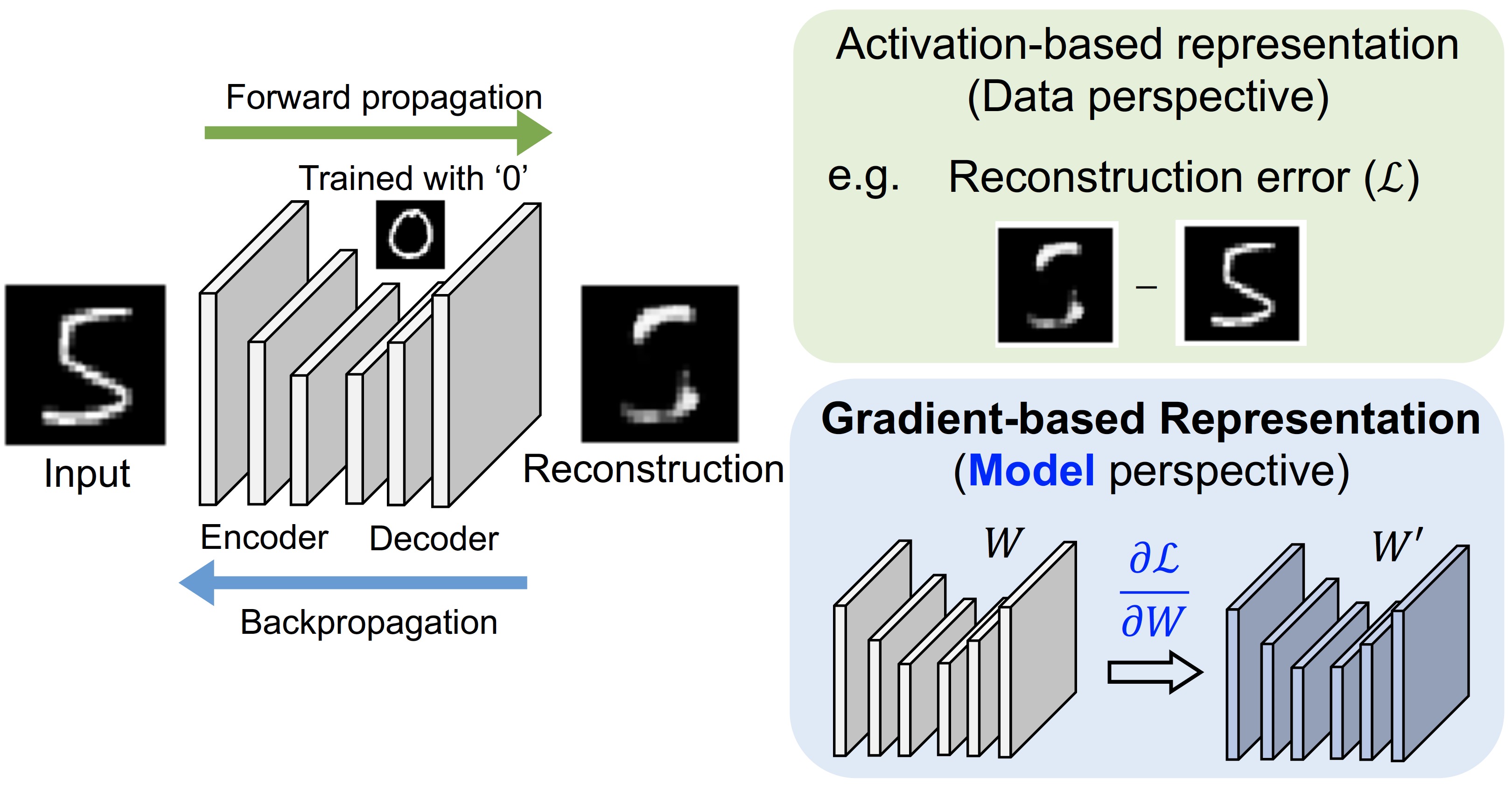
G. Kwon, M. Prabhushankar, D. Temel, and G. AlRegib, “Backpropagated Gradient Representations for Anomaly Detection,” In Proceedings of the European Conference on Computer Vision (ECCV), 2020.
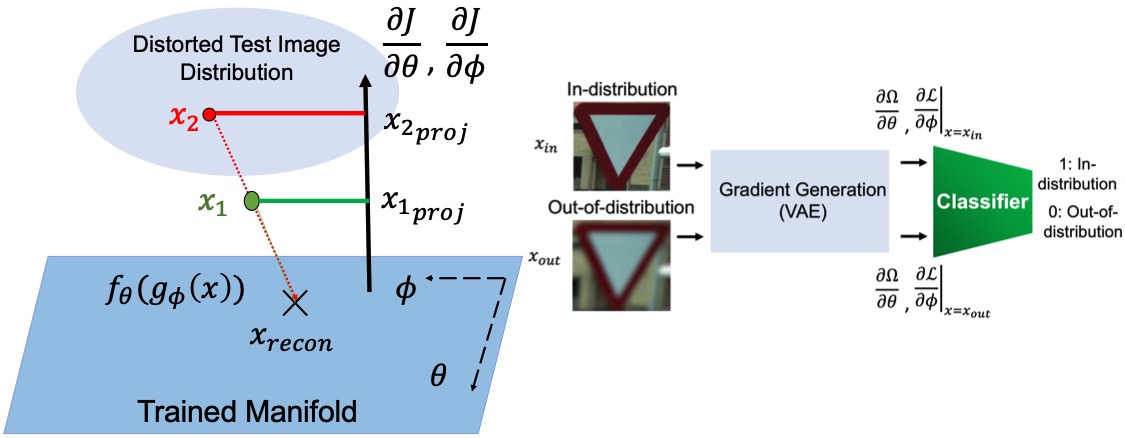
G. Kwon*, M. Prabhushankar*, D. Temel, and G. AlRegib, “Distorted Representation Space Characterization Through Backpropagated Gradients,” 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 2019, pp. 2651-2655. (* : equal contribution, Best Paper Award (top 0.1%))